示例:构建一个Selenium自动化测试用例
需求:
访问百度主页,搜索某个关键词,并验证搜索结果页面的标题是”被搜索的关键词“+”_百度搜索“。以”GUI自动化测试“为例,搜索结果页面的标题应该是”GUI自动化测试_百度搜索“。
在开始之前手动进行验证
以Edge浏览器为例

手动验证的结果为:搜索结果的页面标题为”GUI自动化测试_百度搜索“,符合预期
自动化测试
在开始使用Selenium进行自动化测试之前,需要下载对应浏览器的WebDriver,如EdgeDriver,ChromeDriver等,Selenium版本越高,支持的浏览器也越多
以Edge为例,首先访问官网Microsoft Edge WebDriver | Microsoft Edge Developer
根据处理器型号下载最新的稳定版本Stable Channel(确保浏览器版本跟WebDriver版本对应)
安装后记住XXXdriver.exe文件路径
接下来就可以编写代码进行自动化测试了,我会分成Python与Java两种语言
Python
Python的项目创建相对简单,步骤如下:
在控制台输入pip install selenium即可为项目环境导入selenium包
参考代码如下
from selenium.webdriver.support import expected_conditions as EC
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.edge.service import Service
from selenium.webdriver.edge.options import Options
from selenium.webdriver.support.wait import WebDriverWait
edge_driver_path = r'e:\edgedriver\msedgedriver.exe' # 替换为你的 EdgeDriver 路径
options = Options()
options.use_chromium = True
service = Service(edge_driver_path)
driver = webdriver.Edge(service=service, options=options)
try:
driver.get("https://www.baidu.com")
search_box = driver.find_element(By.NAME, "wd")
search_box.send_keys("GUI自动化测试")
search_box.send_keys(Keys.RETURN)
WebDriverWait(driver, 10).until(
EC.title_contains("GUI自动化测试_百度搜索")
)
actual_title = driver.title
print(f"实际标题:{actual_title}")
assert "GUI自动化测试_百度搜索" in actual_title, "页面标题不匹配"
print("测试通过:页面标题匹配")
finally:
input("按 Enter 键关闭浏览器...")
driver.close()
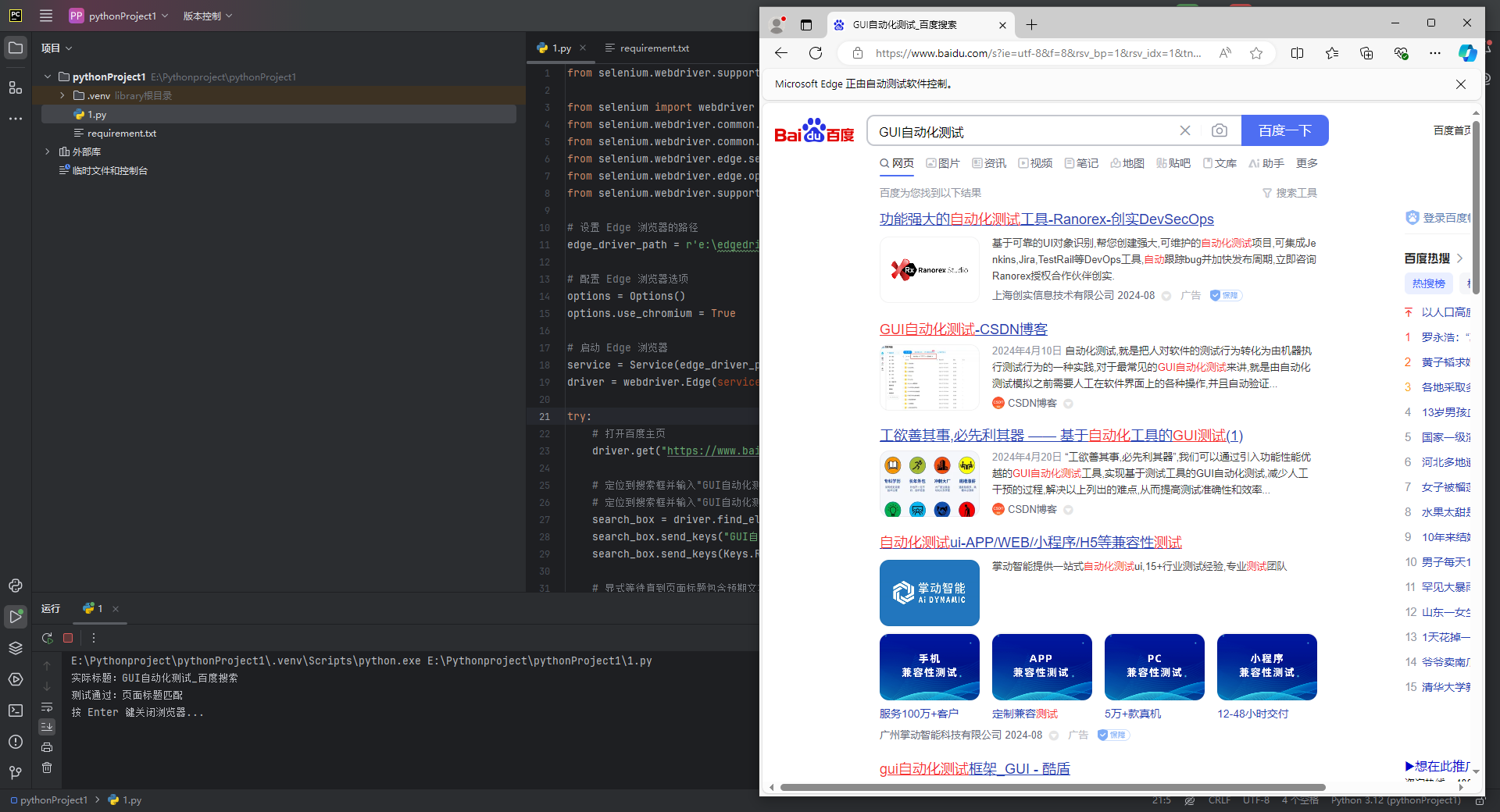
运行结果如下图所示,控制台会显示代码中规定的测试结果
下面来解释代码
edge_driver_path规定了EdgeDriver的路径,程序通过访问这个路径来打开浏览器,路径要指明到exe文件。其中路径前的r表示转义字符
options = Options()创建了一个浏览器配置类,通过调用Options的方法来对浏览器进行配置,是创建webdriver类的入参之一。代码中的options.use_chromium = True表示浏览器使用了Chrome内核。新版的Edge浏览器均使用了Chrome内核。如果读者使用的是非Chrome内核的旧版Edge浏览器,这一项要改为False
service = Service(edge_driver_path)创建了一个浏览器服务类,该类指定了浏览器的启动路径,是创建webdriver类的入参之一
driver = webdriver.Edge(service=service, options=options)这行代码创建了webdriver类的一个实例,其中.Edge表明了调用了webdriver包的edge方法创建类(笔者实测使用.Chrome方法也能成功创建,可见使用同一内核的浏览器可以互相调用其方法)创建成功的webdriver实例表现为新打开了一个浏览器
driver.get("https://www.baidu.com")使用刚才打开的浏览器访问指定页面,这里为百度首页
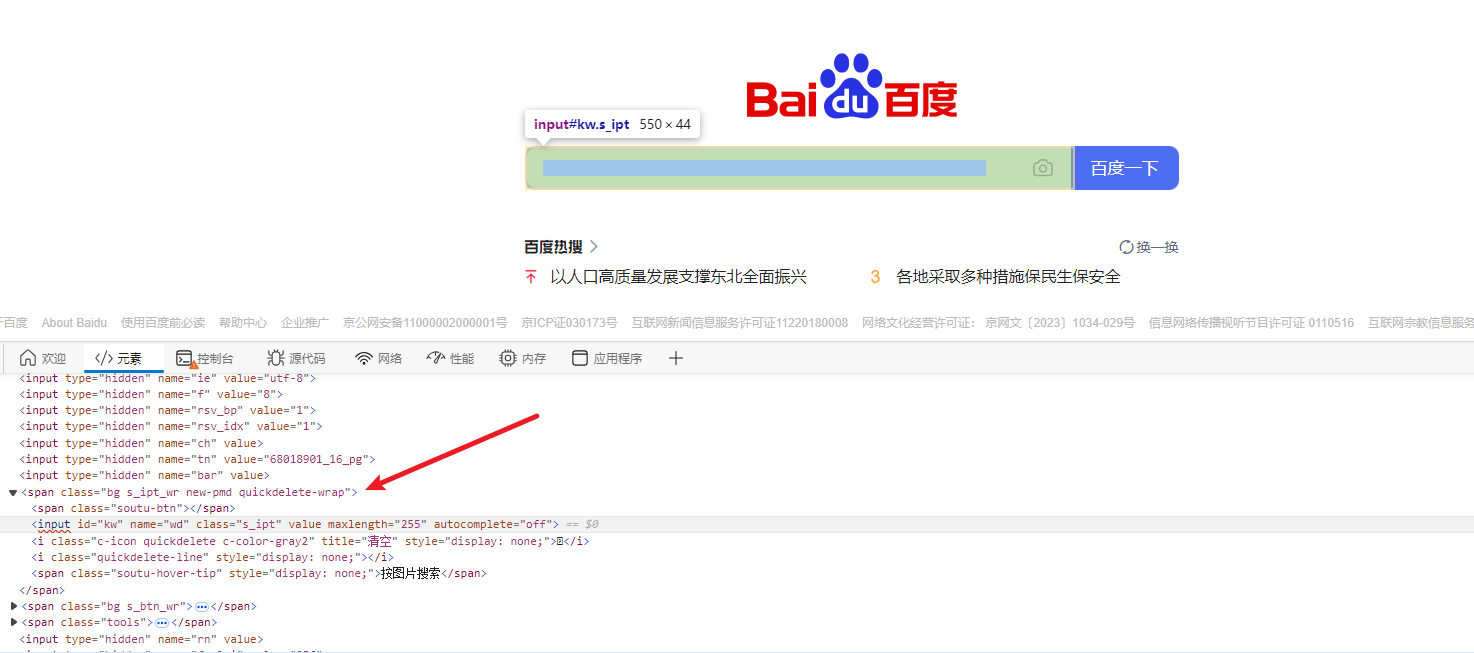
search_box = driver.find_element(By.NAME, "wd")这里通过搜索网页的元素(可通过F12查看)来找到指定的组件,如图所示,搜索框组件的id为kw,name为wd,因此可以通过搜索name(By.NAME)和id(By,ID)来搜索唯一控件,如果网页内控件name不唯一,则通过id来搜索
send_keys模拟了键盘输入,两条语句分别模拟了输入指定内容和输入回车键
WebDriverWait(driver, 10).until(
EC.title_contains("GUI自动化测试_百度搜索")
)
由于网页响应通常需要时间,因此两行代码为显式等待(即打开页面等待)直到页面标题包含预期文本
后续代码为获取页面标题和对返回的结果进行断言
Java
由于实现逻辑大致相同,因此对于Java只讲解项目配置,其他部分直接给出代码
以maven项目为例
项目的pom.xml文件中,在<dependencies></dependencies>中添加如下内容<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-java</artifactId>
<version>4.23.0</version>
</dependency>
其中版本号建议选择4.0以上,旧版本的selenium的部分方法入参与新版本有区别,且对于一些浏览器的支持较差
添加之后加载项目
编写代码如下
package org.example;
import org.openqa.selenium.By;
import org.openqa.selenium.Keys;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.edge.EdgeDriver;
import org.openqa.selenium.edge.EdgeOptions;
import org.openqa.selenium.support.ui.ExpectedConditions;
import org.openqa.selenium.support.ui.WebDriverWait;
import java.time.Duration;
import java.util.Scanner;
public class BaiduSearchTest {
public static void main(String[] args) {
// 设置 Edge 浏览器的路径
System.setProperty("webdriver.edge.driver", "e:\\edgedriver\\msedgedriver.exe"); // 替换为你的 EdgeDriver 路径
// 配置 Edge 浏览器选项
EdgeOptions options = new EdgeOptions();
// 启动 Edge 浏览器
WebDriver driver = new EdgeDriver(options);
try {
// 打开百度主页
driver.get("https://www.baidu.com");
// 定位到搜索框并输入"GUI自动化测试"
WebElement searchBox = driver.findElement(By.name("wd"));
searchBox.sendKeys("GUI自动化测试");
searchBox.sendKeys(Keys.RETURN); // 执行搜索
// 显式等待直到页面标题包含预期文本
WebDriverWait wait = new WebDriverWait(driver, Duration.ofSeconds(10));
wait.until(ExpectedConditions.titleContains("GUI自动化测试_百度搜索"));
// 打印实际标题
String actualTitle = driver.getTitle();
System.out.println("实际标题:" + actualTitle);
// 验证页面标题
assert actualTitle.contains("GUI自动化测试_百度搜索") : "页面标题不匹配";
System.out.println("测试通过:页面标题匹配");
} catch (Exception e) {
e.printStackTrace();
} finally {
// 等待用户输入后关闭浏览器
System.out.println("按 Enter 键关闭浏览器...");
new Scanner(System.in).nextLine();
driver.quit();
}
}
}上述代码中,不管是Python还是Java,其逻辑都大差不差,如下:
- 打开浏览器(支持webdriver的任一浏览器,chorme,edge,firefox等)
- 在URL栏自动输入百度的网址
- 打开百度主页后,在输入框自动输入”GUI自动化测试“并执行搜索
- 返回搜索结果页面
- 验证搜索结果的页面标题是否是”GUI自动化测试_百度搜索“
这样,一个简单的Selenium自动化测试案例就完成了
Selenium的实现原理
刚才的测试用例是基于Selenium4,也就是Selenium+WebDriver的方案,在Selenium的历代版本中,V1.0的核心是Selenium RC与后续版本的差异最大相比2.0来说,3.0和4.0只是删除了对Selenium RC的支持。
因此,实现原理部分主要按照1.0和2.0/3.0/4.0两部分来说明
Selenium 1.0的工作原理
Selenium 1.0,又称为Selenium RC(Remote Control)。其原理是:JavaScript代码可以获取页面上的任何元素并执行操作。但是因为同源政策(只有来自相同域名、端口和协议的JavaScript代码才能被浏览器执行)所以Selenium RC必须“欺骗”被测站点,让其认为注入的代码是同源的。
总的来说Selenium RC分为两大部分:Selenium Server和客户端库(Client Libraries)。其中,Selenium Server是核心部分
Selenium Server
Selenium Server是一个Java程序,其主要作用包括:启动和关闭浏览器、加载Selenium Core到浏览器中、代理客户端的命令并将其发送到浏览器中执行
客户端库(Client Libraries)
用户编写的脚本通过客户端库与Selenium Server通信
流程
- 测试脚本编写
- 用户使用客户端库编写测试脚本,包含对浏览器执行各种操作的命令,如点击、输入文本、导航到URL等
- 启动Selenium Server
- 在执行测试脚本之前,用户需要手动启动Selenium Server。
- 测试脚本与Selenium Server通信
- 测试脚本通过客户端库与Selenium Server建立连接
- Selenium Server启动浏览器
- Selenium Server根据测试脚本中的命令,启动指定的浏览器,并将Selenium Core(一个基于JavaScript的测试引擎)注入到浏览器中
- 浏览器执行命令
- Selenium Core通过JavaScript在浏览器中执行用户的测试命令,如操作DOM元素、进行页面导航等。
- 结果返回
- 浏览器执行完命令后,Selenium Core将执行结果返回给Selenium Server,Selenium Server再将结果返回给客户端库。客户端库最终将这些结果显示给用户
Selenium WebDriver的工作原理
Selenium RC由于性能较差,因此从Selenium 2.0开始,逐渐开始用Selenium WebDriver代替RC
Selenium WebDriver的原理是使用浏览器原生的WebDriver实现页面操作,是典型的服务器-客户端模式,服务器端就是本地或远程服务器。
- 当使用Selenium WebDriver启动Web浏览器时,后台会同时启动基于WebDriver Wire协议的Web服务作为Selenium的远程服务器,并将其与浏览器绑定。绑定完成后,远程服务器就开始监听客户端的操作请求。
- 执行测试时,测试用例会作为客户端,将需要执行的页面操作请求以HTTP请求的方式发送给远程服务器。该HTTP请求的正文以WebDriver Wire协议规定的JSON格式来描述需要浏览器执行的操作请求。
- 执行测试时,测试用例会作为客户端,将需要执行的页面操作请求以HTTP请求的格式发送给远程服务器。该HTTP请求的正文以WebDriver Wire协议规定的JSON格式来描述需要浏览器执行的具体操作。
- 远程服务器接收到请求后,会对请求进行解析,并将解析结果发给WebDriver,由WebDriver实际执行浏览器的操作
- WebDriver可以看作直接操作浏览器的原生组件,所以搭建测试环境时,通常需要下载对应的WebDriver。
- 前文的百度搜索的测试用例时直接在本地启动测试服务的,并没有使用到远程服务器。
测试脚本和测试数据的解耦
GUI自动化脚本尤其适用于需要回归测试页面功能的场景,但在正式开发GUI自动化脚本之前,需要了解一下测试脚本和测试数据的解耦
测试脚本和测试数据的解耦
以上面百度搜索的测试用例为例,在这个测试脚本中,既有测试数据又有测试操作,而且所有的操作都集中在一个脚本中。如果在测试脚本中硬编码测试数据,测试脚本的灵活性会非常低。另外,对于那些具有相同页面操作只是测试输入数据不同的用例来说,就会存在大量重复的代码。因此,我们需要将测试数据和测试脚本分离。通过数据来驱动测试脚本的运行,即有多少条测试数据,就运行多少次测试脚本。
页面对象模型
早期的GUI测试脚本
下面的伪代码是一个典型的早期GUI测试脚本的结构
findElementByName("username").input("testuser001");
findElementByName("password").input("password");
findElementByName("login_ok_button").click();
wait(3000);
findElementByName("book_homepage").click();
wait(3000);
findElementByName("bookname_search_field").input("book name");
findElementByName("search_button").click();
wait(3000);
assert(...);
findElementByName("logout_button").click();
findElementByName("logout_ok_button").click();
这段伪代码的可读性比较差,主要体现在:
逻辑层次不够清晰,既有页面元素的定位查找,又有对元素的操作
可读性差,导致后期脚本的维护难度增大
逐行阅读只能读出每一行实现的功能,无法一眼看出整个脚本的业务流程
通用步骤会在大量测试脚本中重复出现,比如登录和退出等,这些操作会在其他的测试用例的脚本中多次重复。因此每当需要修改参数时,都需要同时修改大量的脚本
基于模块化思想的GUI测试用例
testcase_001()
{
login("testuser001","password");
search("bookname");
logout();
}
login(username,password)
testcase_001()
{
login("testuser001","password");
search("bookname");
logout();
}
login(username,password)
{
findElementByName("username").input(username);
findElementByName("password").input(password);
findElementByName("login_ok_button").click();
wait(3000);
}
search(bookname)
{
findElementByName("book_homepage").click();
wait(3000);
findElementByName("bookname_search_field").input(bookname);
findElementByName("search_button").click();
wait(3000);
assert(...);
}
logout()
{
findElementByName("logout_button").click();
findElementByName("logout_ok_button").click();
}实际工程应用中,第1~6行的测试用例和第8~30行的操作函数通常不会放到一个文件中。
这种模块化的设计思路的好处如下:
解决了脚本可读性差的问题,使脚本的逻辑层次更清晰
解决了通用步骤会在大量测试脚本中重复出现的问题,操作函数可以被多个测试用例共享。
但是,模块化的测试用例并没有完全解决早期GUI自动化测试的主要问题,如每个操作函数内部的脚本可读性问题,而且新增了如何把握操作函数粒度的问题,以及如何衔接两个操作函数之间的页面。
基于页面对象模型实现GUI测试用例
页面对象模型的核心理念使,以页面(Web页面或原生应用页面)为单位来封装页面上的控件和控件的部分操作。而测试用例(或者说操作函数),基于页面封装对象来完成具体的界面操作,最典型的模式是”XXXpage.YYYComponent.ZZZOperation”。
Class loginPage{
username_input = findElementByName("username");
password_input = findElementByName("password");
login_ok_button = findElementByName("login_ok_button");
login_cancel_button = findElementByName("login_cancel_button");
}
login(username,password)
{
loginPage.username_input.input(username);
loginPage.password_input.input(password);
loginPage.login_ok_button.click();
}这样的代码结构可以清楚地看到在什么页面上执行了什么操作,也可以更容易地将具体的执行步骤转换成测试脚本,同时代码的可读性以及可维护性大幅度提高。
业务抽象
操作函数的粒度
操作函数的粒度指:一个操作函数应该包含多少个操作步骤才是合适的
粒度太大会降低操作函数的可重用性和,粒度太小就失去了操作函数封装的意义
操作函数的粒度控制很大程度上取决于项目的实际情况,往往以完成一个业务流程为主线,抽象出其中的 “高内聚低耦合”的操作步骤集合。
在一个业务流程中,往往将涉及到多个 逻辑上相对独立的操作步骤包装成一个操作函数。
页面衔接
操作函数和操作函数之间往往会有页面衔接的问题,即前序操作完成后的最后一个页面,必须时后续操作函数的第一个页面。如果连续的两个操作函数之间无法用页面衔接,就需要在中间假如额外的页面跳转代码,或者在操作函数内部假如特定的页面跳转代码
业务流程抽象
业务流程抽象,是基于操作函数更接近于实际业务的更高层次的抽象方式。基于业务流程抽象实现的测试用例往往灵活性会非常好,可以很方便地组装出各种测试用例。
以下列业务流程为例:已注册的用户登录电商平台购买指定的图书,然后退出。基于业务流程抽象的测试用例伪代码如下:
loginFlowParameters loginFlowParameters = new LoginFlowParameters();
loginFlowParameters.setUserName("username");
loginFlowParameters.setPassword("password");
LoginFlow loginflow = new LoginFlow(loginFlowParameters);
loginFlow.execute();
SearchBookFlowParameters searchBookFlowParameters = now SearchBookFLowParameters();
searchBookFlowParameters.setBookName("bookname");
SearchBookFlow searchBookFlow = SearchBookFlow(searchBookFlowParameters);
searchBookFlow.withStartPage(loginFlow.getEndPage()).execute();
CheckoutBookFlowParameters checkoutBookFlowParameters = new CheckoutBookFlowParameters();
checkoutBookFlowParameters.setBookID(searchBookFlow.getOutPut().getBookID());
CheckoutBookFlow checkoutBookFlow = new CheckoutBookFlow(checkoutBookFlowParameters);
checkoutBookFlow.withStartPage(searchBookFlow.getEndPage()).execute();
LogoutFlow logoutFlow = new LogoutFlow();
logoutFlow.withStartPage(checkoutBookFlow.getEndPage()).execute();这段伪代码按顺序调用了LoginFlow,SearchBookFlow,CheckOutBookFlow,LogoutFlow四个业务流程。这四个业务流程都是作为独立的类封装的,可以很方便地重用并灵活组合。类的内部实现通常是调用操作函数。而在操作函数内部则基于页面对象模型完成具体的页面控件操作。
对于每一个业务流程类,都会有相应的业务流程输入参数类与之一一对应。具体如下
1、初始化一个业务流程输入参数类的实例
2、给这个实例赋值
3、用这个输入参数类的实例来初始化业务流程类的实例
4、执行这个业务流程实例
业务流程的优点
1、业务流程的封装更接近实际业务
2、基于业务流程的测试用例非常标准化,遵循准备参数,实例化流程和执行流程这三个步骤,非常适用于测试代码的自动生成
3、因为更接近实际业务,所以可以很方便地和行为驱动开发(Behavior Driver Development,BDD)结合